Puppeteer 사용방법 - 1. Screenshot, PDF
Puppeteer 알아보기
클라우드 솔루션이 많아지고 업무도 웹상에서 많이 하다보니 웹사이트에서의 자동화가 이뤄지면 편해지는게 많을 것 같다. Pupperteer 를 써보니 실제 사용자의 행동을 코드로 똑같이 구현할 수 있었다. 응용하면 더 많은 데이터를 수집하고 더 능률적으로 일할 수 있을것 같아서 정리를 해봤다.
Puppeteer 로 할 수 있는 것들 참고 공식 사이트
- 페이지의 스크린샷 또는 PDF를 생성
- SPA (Single-Page Application)의 콘텐츠를 읽어와서 미리 생성된 콘텐츠로 재생성
- 자동화된 폼 전송, UI 테스트, 키보드 입력 등 가능
- 최신화된 자동화 테스트 환경 생성. 최신 버전의 Javascript와 브라우저 기능이 적용된 최신 버전의 크롬에서 바로 테스트 가능
- 사이트의 성능 이슈를 진단하기 위한 timeline 추적
- 크롬 확장 프로그램 테스트
Puppeteer 기본 개념
Puppeteer 는 Node 라이브러리이고 아래의 개념이 class로 구현되어 있다.
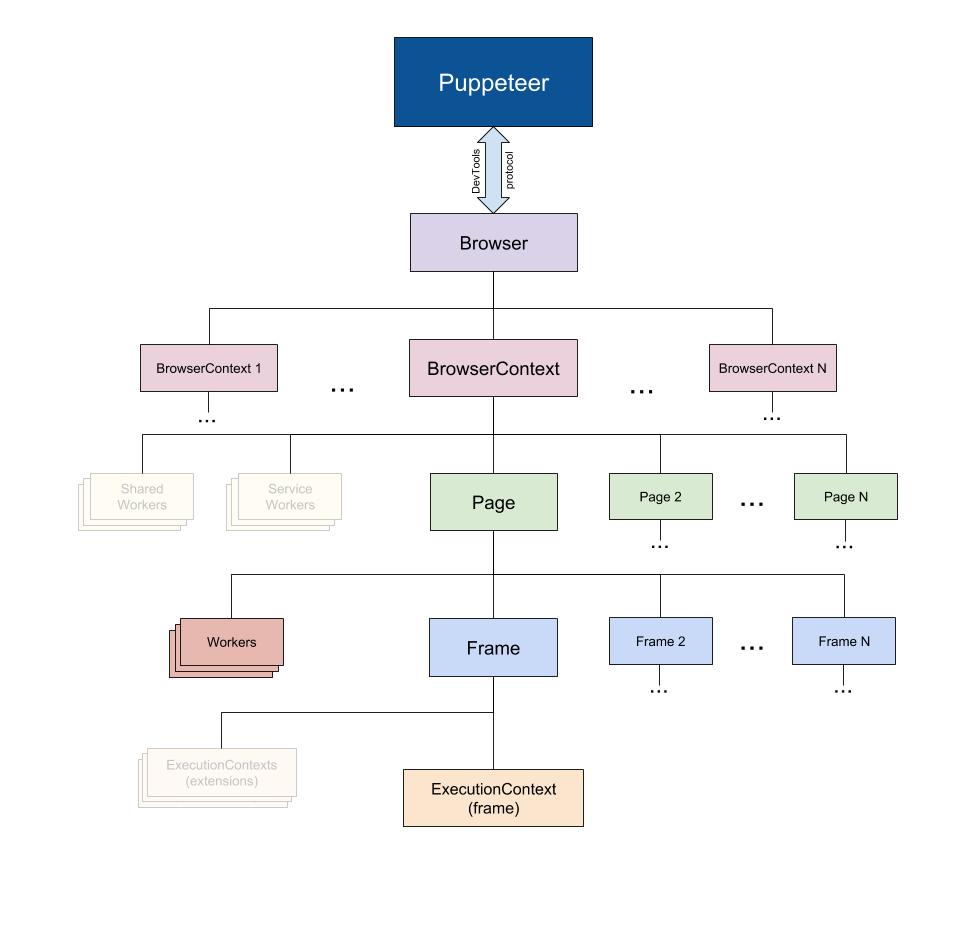
PuppeteerDevTools Protocol을 사용하는 브라우저와 연동Browser여러개의 페이지를 가질 수 있는 owner.Page프레임을 갖고 있음. 여러개의Frame소유 가능.Frame실행할 수 있는 최소 실행 단위. 설정된context를 수행하는 기본 단위.
Scenarios
사이트 운영을 하는 입장으로서 사이트가 연간 어떻게 변하는지 관리할 필요가 있다. 스크린샷을 저장하는 프로그램을 주기적으로 실행시켜서 사이트의 히스토리를 관리하면 좋을것같다.
Screen shot 생성
모든 Puppeteer class 는 Promise 를 리턴한다. 따라서 async/await로 구현이 가능하다. Naver 메인 페이지를 캡쳐해봤다.
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage()
await page.goto('http://www.naver.com')
await page.screenshot({
fullPage: true,
path: `naver-mainpage-${new Date().toISOString().substr(0, 10)}.jpeg`
})
//pdf
// await page.pdf({
// path: `page-screen-${new Date().toISOString().substr(0, 10)}.pdf`
// })
await browser.close()
})
PDF로 생성
프로젝트를 하다보면 산출물이 엄청나게 나온다. 매번 Office 문서로 작업하고 History를 위해 날짜별로 파일을 생성해야 한다. 어차피 볼사람만 열어보는 산출물을 효율적으로 관리하기 위해서 웹으로 산출물 문서를 만들고 Puppeteer로 PDF 로 생성하면 좋을것같다.
Gitbook 이라는 서비스가 있는데 온라인 document 를 아주 깔끔하게 보여준다. Github 과 연동해서 History관리도 정말 좋다. 아쉬운 점은 생성된 문서에 대한 Export를 JSON으로 지원하는데 재사용이 불가능한 정도다. 이럴 때 puppeteer로 생성된 온라인 문서를 PDF 로 저장하면 문서를 생성하는 사람도 완성된 문서를 전달받는 사람도 기분이 좋을것 같다.


puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://launch.gitbook.io/docs/');
await page.pdf({
path: `page-pdf-${new Date().toISOString()}.pdf`
})
await browser.close()
})
개발에서 컨설팅쪽으로 점차 옮겨가면서 문서의 중요성(고객이 원하니까)을 많이 느끼고 있어서 다음 프로젝트에서는 이런 방식을 제안해봐야겠다.
Redirect 처리
관리하는 사이트 중에는 지정된 페이지로 가기전에 SSO 를 위해서 다른 도메인을 거치는 경우가 있었다. 기본 코드로 작업할 경우에는 빈 이미지가 생성된다. 지정된 페이지에 도착할때가지 기다리게 하는 코드를 추가 했다. 네트워크 상태에 따라서 추가 옵션이 필요할수도 있다.
await page.goto('http://www.naver.com')
await page.waitForNavigation()
await page.screenshot(...)
Redirect 가 아닌 페이지에서
waitForNavigation를 사용할 경우 대기(30초)하다가 Timeout 에러를 발생시킨다. Redirection을 수행하는 조건을 확인해서 예외처리를 해야한다.
CSS 추가하기
스크린샷을 저장하기 전에 특정 영역을 강조하도록 하고싶었다. 불러온 페이지에서 CSS를 삽입 시킬 하여 프레임의 디자인을 약간 수정할 수 있다. 개발영역과 퍼블리싱 영역이 페이지에 해야 하는 작업을 완료했는지 확인하기 위해서 페이지를 CSS 로 수정하여 스크린샷을 찍었다. 모든 페이지를 열어서 확인하지 않고 몇몇 이미지의 눈대준 확인만으로도 작업검수가 가능했다. DOM 검수까지 확인해서 로그로 남겨도 되겠지만 예외가 많아서 그정도의 자동화보다 아직은 눈이 빠른것같다.
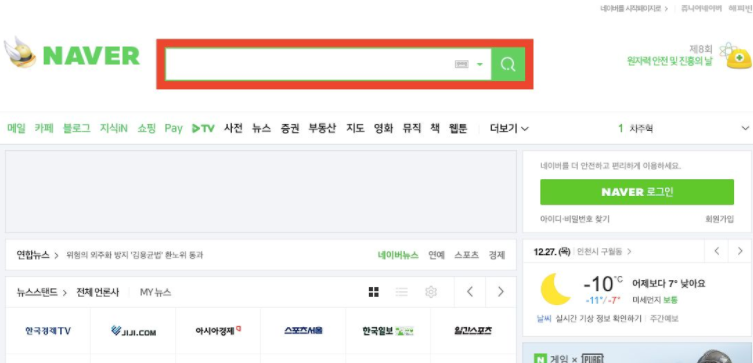
// define the page
await page.goto('http://www.naver.com');
await page.addStyleTag({
content: '#search {border: 1em solid red;}'
})
// do screenshot
Mobile 페이지
모바일의 중요성이 더 높아지고 많은 사이트가 반응형이기 때문에 작은 화면의 사이트 화면 히스토리도 중요할것같다. Puppeteer 에서는 접속 브라우저의 User Agent 를 다시 설정할 수 있다. User Agent 를 뭘로 설정하냐는 문제가 있는데, 정의된 Node 라이브러리도 있겠지만 그냥 정리된 사이트에서 복사해서 썼다.
const ua_IOS = 'Mozilla/5.0 (iPhone; ...'
const page = await browser.newPage();
await page.setUserAgent(ua_IOS)
await page.goto('http://www.naver.com');
Summary
페이지 스크린샷은 제일 기본적인것으로 설명하고 있는데 코드가 이미지나 PDF 로 연결된다는게 뭔가 생산적인일을 하는것 같은 느낌이 들었다. 그래서 더 확장해보고 싶고 실제 프로젝트에도 적용해보고싶다. 대용량 스크래핑같은것을 하기에는 아직 내가 Pupperteer에 대한 성능 숙련도같은게 부족하니까 좀 더 알아보고 실무에 적용해봐야겠다.